
itgle.com
如果对关系emp(eno, ename, salary)成功执行下而的SQL语句:CREATE CLUSTER INDEX name_index ON emp(salary)其结果是( )。A) 在emp表上按salary升序创建了一个聚簇索引B) 在emp表上按salary降序创建了一个聚簇索引C) 在emp表上按salary升序创建了一个惟一索引D) 在emp表上按salary降序创建了一个惟一索引A.B.C.D.
题目
如果对关系emp(eno, ename, salary)成功执行下而的SQL语句:
CREATE CLUSTER INDEX name_index ON emp(salary)
其结果是( )。
A) 在emp表上按salary升序创建了一个聚簇索引
B) 在emp表上按salary降序创建了一个聚簇索引
C) 在emp表上按salary升序创建了一个惟一索引
D) 在emp表上按salary降序创建了一个惟一索引
A.
B.
C.
D.
相似考题
更多“如果对关系emp(eno, ename, salary)成功执行下而的SQL语句: CREATE CLUSTER INDEX name_index ON ”相关问题
-
第1题:
如果对关系emp(eno,ename,salary)成功执行下面的SQL语句: CREATE CLUSTER INDEXname_index ON emp(salary)对此结果的正确描述是
A.在emp表上按salary升序创建了一个聚簇索引
B.在emp表上按salary降序创建了一个聚簇索引
C.在emp表上按salary升序创建了一个唯一索引
D.在emp表上按salary降序创建了一个唯一索引
正确答案:A
解析:通过CREATEINDEXname_indexONemp(salary)判断语句要在emp表上按salary创建索引nameindex,CLUSTER表示要建立的索引是聚簇索引,索引排列顺序的缺省值为ASC(升序)。因此本题的答案为A。 -
第2题:
如果对关系emp(eno,ename,salary)成功执行下面的SQL语句: CREATE CLUSTER INDEXname_index ON emp(salary) 对此结果的正确描述是_______。
A.在emp表上按salary升序创建了一个聚簇索引
B.在emp表上按salary降序创建了一个聚簇索引
C.在emp表上按salary升序创建了一个惟一索引
D.在emp表上按salary降序创建了一个惟一索引
正确答案:A
解析:语句CREATE CLUSTER INDEX name_index ON emp(salary)的语义是在表emp的列salary上创建一个名为name_index的聚簇索引,而且表emp中的记录是按salary升序存放的。 -
第3题:
(33)如果对关系 emp(eno, ename, salary)成功执行下面的SQL语句:
CREATE CLUSTER INDEX name_index ON emp(salary)
其结果是
A)在 emp表上按sal娜升序创建了一个聚簇索引
B)在 emp表上按salary降序创建了一个聚簇索引
C)在 emp表上按salary升序创建了一个唯一索引
D)在 emp表上按salary降序创建了一个唯一索引
正确答案:A
-
第4题:
● 设有职工表emp(Eno,Ename,Sex,Age)(Eno为职工号,Ename为职工姓名,Sex为性别,Age为年龄)和salary(Eno,Hour,Month,Wage)(Hour为工作时长为多少小时,Month表示几月份,Wage为薪水),建立一个视图V-Salary(Eno,Ename,Hour,Month,Wage),并按Eno升序排序的SQL语句为:
(1)CREATE ( )
AS SELECT emp.Eno,emp.Ename ,salary.Hour,salary.Month,salary.Wage
FROM emp, salary
WHERE emp.Eno=salary.Eno
ORDER BY ENO
在此视图上查均月工资在3000以上的职工工资情况的SQL语句为:
SELECT Eno,Ename,AVG(Wage)
FROM V-Salary
GROUP BY ( )
HAVING AVG(Wage)>3000
( )
A. CREATE TABLE V-Salary(emp.Eno,emp.Ename,salary.Hour,salary.Month,salary.Wage)
B. CREATE VIEW V-Salary(Eno,Ename,Hour,Month,Wage)
C. CREATE TABLE V-Salary(Eno,Ename,Hour,Month,Wage)
D. CREATE INDEX V-Salary(Eno,Ename,Hour,Month,Wage)
( )
A. Eno B.Ename
C.Month D.Wage
正确答案:B,A
此题第一空容易,考查考生是否了解建立视图的语法规则。第二空也比较明显,在salary中有字段Month,用于标识当前记录是哪个月的工资记录,这就意味着在数据表中,一个Eno对应着多个工资记录,要计算平均值,可以先按Eno进行分组,再求工资平均值,所以第2空填A。 -
第5题:
对于第7题的两个基本表,有一个SQL语句: SELECT ENO, ENAME FROM EMP WHERE DNO NOT IN (SELECT DNO FROM DEPT WHERE DNAME='金工车间');其等价的关系代数表达式是:______。
A.πENO,ENAME(σDNAME≠'金工车间'(EMP
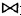 DEPT))
DEPT))B.πENO,ENAME

C.πENO,ENAME(EMP)-πENO,ENAME (σDNAME='金工车间'(EMP
DEPT))D.πENO,ENAME (EMP)-πENO,ENAME (σDNAME≠'金工车间'(EMP
DEPT))正确答案:C