
itgle.com
n足够大,P不接近于0或1,样本率与总体率比较,统计量u为A.|p-π| SpB.|p1-P2 | σpC.|p1-P2 | SpD.|p-π|σE.|p-π|σp
题目
n足够大,P不接近于0或1,样本率与总体率比较,统计量u为
A.|p-π| Sp
B.|p1-P2 | σp
C.|p1-P2 | Sp
D.|p-π|σ
E.|p-π|σp
相似考题
更多“n足够大,P不接近于0或1,样本率与总体率比较,统计量u为A.|p-π| SpB.|p1-P2 | σpC.|p1-P2 | SpD.|p ”相关问题
-
第1题:
n足够大,P不接近于O或1,样本率与总体率比较,统计量u为
A.Ip-ΠI/Sp
B.Ip1-p2I/σp
C.Ip1-p2I/Sp
D.Ip-ΠI/σ
E.Ip-ΠI/σp
正确答案:E
-
第2题:
当样本含量足够大,总体阳性率与阴性率均不接近于0和1,总体率95%可信区间的估计公式为
A.P±2.58Sp
B.P±1.96Sp
C.P±1.96Sx
D.P±2.58Sx
E.X±1.96Sx
正确答案:B
-
第3题:
样本率与总体率比较,统计量u为
A.|P-π|SP
B.|P-π|σP
C.|P-π|SP
D.|P-π|σ
E.|P-π|σP
正确答案:E
略 -
第4题:
n足够大,P不接近于0或1,样本率与总体率比较,统计量U为A.B.C.D.SXn足够大,P不接近于0或1,样本率与总体率比较,统计量U为
A.

B.

C.
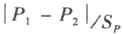
D.

E.
 正确答案:E
正确答案:E
-
第5题:
n足够大,P不接近于O或1,样本率与总体率比较,统计量u为A.|P-π|/σ
B.|P1-P2|/Sp
C.|P1-P2|/σp
D.|P-π|/Sp
E.|P-π|/σp答案:E解析:n足够大,P不接近于0或1,样本率与总体率比较,统计量u为|P-π/σp。 -
第6题:
满足下列何种条件,泊松分布可认为近似正态分布A.λ≥20
B.n足够大
C.方差等于均数
D.总体均数不大
E.样本率p不接近于0或1答案:A解析: -
第7题:
当样本含量足够大时,样本率又不接近0或1时,以样本率推断总体率95%可信区间的计算公式为A.p+1.645s
B.π±1.96σ
C.p±2.58s
D.X±1.96s
E.p±1.96s 答案:E解析:
答案:E解析: -
第8题:
对于二项分布的资料符合下面哪种情况时,可借用正态分布处理()。
- A、样本含量n足够大,以致np(p为样本率)与n(1-p)都较大时
- B、样本含量n足够大,样本率p足够小时
- C、样本率p=0.5时
- D、样本率p接近1或0时
- E、样本率p足够大时
正确答案:A -
第9题:
当样本含量足够大,总体阳性率与阴性率均不接近于0和1,总体率95%可信区间的估计公式为()
- A、P±2.58Sp
- B、P±1.96Sp
- C、P±1.96Sx
- D、P±2.58Sx
- E、X±1.96Sx
正确答案:B -
第10题:
当样本含量足够大,总体阳性率与阴性率均不接近0和1,总体率95%可信区间的估计公式为()
- A、P±2.58Sp
- B、P±1.96Sp
- C、P±1.96Sx
- D、P±2.58Sx
- E、X±1.96Sx
正确答案:B -
第11题:
单选题对于二项分布的资料符合下面哪种情况时,可借用正态分布处理()。A样本含量n足够大,以致np(p为样本率)与n(1-p)都较大时
B样本含量n足够大,样本率p足够小时
C样本率p=0.5时
D样本率p接近1或0时
E样本率p足够大时
正确答案: A解析: 暂无解析 -
第12题:
填空题求得两块麦田的锈病率的相差的95%置信区间为2.56%≤p1-p2≤10.7%p,则应在α=0.05水平上H0,HA。正确答案: 否定,接受解析: 暂无解析 -
第13题:
若进行u检验,公式为
A.u=|P1-P2|/SP1-P2
B.u=|P-π|/SP
C.u=|P1-P2|/σP
D.u=|P1-P2|/SP
E.u=|P-π|/σP
正确答案:D
-
第14题:
n足够大,P不接近于0或1,样本率与总体率比较,统计量u为
A:|P-π|/σp
B:|P1-P2|/Sp
C:|P1-P2|/σp
D:|P-π|/Sp
E:|P-π|/σ
正确答案:A
解析:n足够大,P不接近于0或1,样本率与总体率比较,统计量u为|P-π|/σp。
-
第15题:
(2003)n足够大,P不接近于0或1,样本率与总体率比较,统计量u为A.|P-π|/SpB.|P-P|/σSXB(2003)n足够大,P不接近于0或1,样本率与总体率比较,统计量u为
A.|P-π|/Sp
B.|P
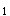 -P
-P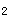 |/σ
|/σ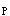
C.|P
-P|/SD.|P-π|/σ
E.|P-π|/σ
正确答案:E
-
第16题:
当样本量足够大时,总体阳性率与阴性率均不接近于0和1,总体率95%的可信区间的估计公式为
A.P±2.58S
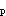
B.P±1.96S
C.P±1.96S

D.P±2.58S
E.X±1.96S
正确答案:B
当样本含量n足够大,且样本率P和(1-p)均不太小,如nP或n(1-P)均5时,样本率的分布近似正态分布。则总体率的可信区间可由下列公式估计,总体率(π)的95%可信区间:P±1.96Sp。 -
第17题:
n足够大.p不接近于0或1,样本率与总体率比较,统计量μ为A.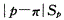
B.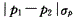
C.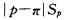
D.|p-π|σ
E.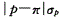 答案:E解析:在样本含量n足够大、样本率p和1-p均不接近于零的前提下,样本率的分布近似于正态分布,样本率和总体率之间、两个样本率之间差异来源的判断可用μ检验。样本率与总体率的比较公式为:
答案:E解析:在样本含量n足够大、样本率p和1-p均不接近于零的前提下,样本率的分布近似于正态分布,样本率和总体率之间、两个样本率之间差异来源的判断可用μ检验。样本率与总体率的比较公式为: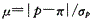 。故选E。
。故选E。 -
第18题:
n足够大,P不接近于O或1,样本率与总体率比较,统计量U,为A.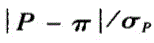
B.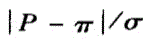
C.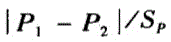
D.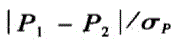
E.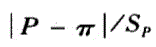 答案:A解析:
答案:A解析: -
第19题:
n足够大,P不接近于0或1,样本率与总体率比较,统计量u为A.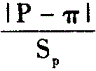
B.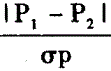
C.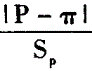
D.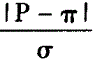
E.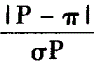 答案:E解析:n足够大,P不接近于0或1,样本率与总体率比较,统计量u为|P-π|/σp。
答案:E解析:n足够大,P不接近于0或1,样本率与总体率比较,统计量u为|P-π|/σp。 -
第20题:
n足够大,P不接近于0或1,样本率与总体率比较,统计量u为()。
- A、∣P-π∣/Sp
- B、∣P1-P2∣/σp
- C、∣P1-P2∣/Sp
- D、∣P-π∣/σ
- E、∣P-π∣/σp
正确答案:E -
第21题:
当样本含量足够大时,样本率又不接近0或1时,以样本率推断总体率95%可信区间的计算公式为()
- A、p±2.58sP
- B、p+1.645sP
- C、p±1.96sP
- D、π±1.96σπ
- E、X±1.96sX
正确答案:C -
第22题:
求得两块麦田的锈病率的相差的95%置信区间为2.56%≤p1-p2≤10.7%p,则应在α=0.05水平上H0,HA。
正确答案:否定;接受 -
第23题:
单选题n足够大,P不接近于0或1,样本率与总体率比较,统计量u为()。A∣P-π∣/Sp
B∣P1-P2∣/σp
C∣P1-P2∣/Sp
D∣P-π∣/σ
E∣P-π∣/σp
正确答案: E解析: 暂无解析